Newsletter - Quality by Design |
|
|
|
HPLC Method Development 스크리닝 디자인 |
|
|
안녕하세요. 랩솔루션즈입니다.
오늘은 Fusion QbD를 이용하여 스크리닝 실험디자인을 해 보고, 그 실험디자인이 통게적으로 어떻게 구성되어 있는지 알아보는 시간을 가져 보겠습니다.
연구하고자 하는 실험변수 및 범위는 아래와 같습니다. |
|
|
Full factorial design 을 사용면 3 * 5 * 3 = 45개 의 실험을 해야 하지만. A and G Optimal design을 사용하면 30 개의 실험을 진행하면 됩니다.
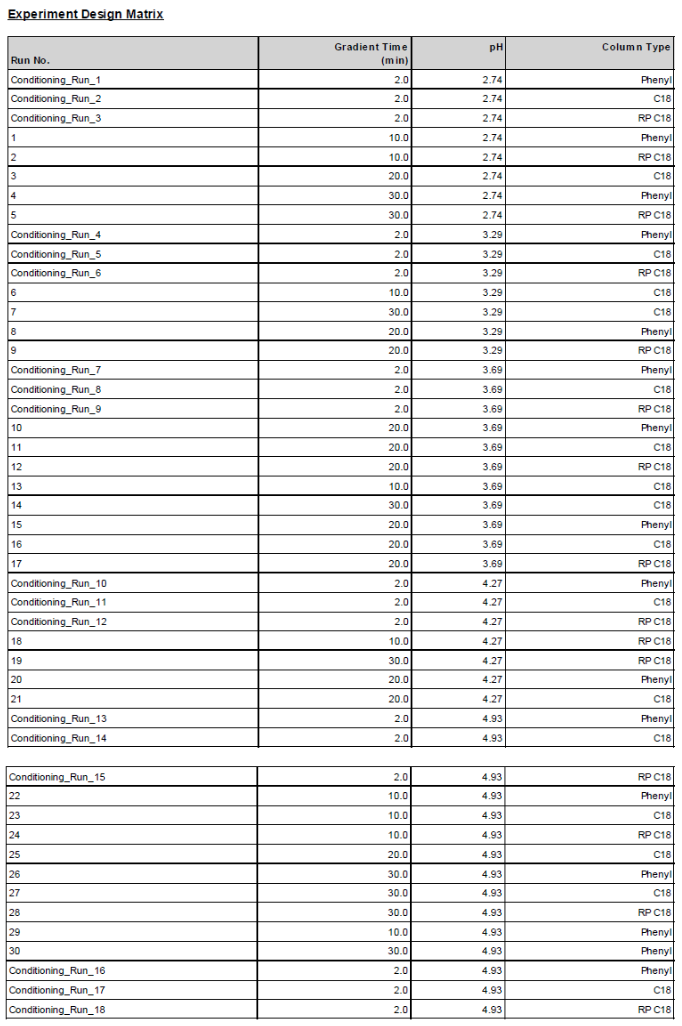
A and G Optimal Design 을 사용하여 만든 Matrix 는 아래와 같습니다. |
|
|
디자인된 실험 Matrix에서 보듯이 pH 가 증가하는 방향으로 실험이 디자인 되었으며 pH가 바뀔때 마다 Condition column 기능을 두어 pH 변동전에 컬럼을 안정화 시키고 있습니다.
이 디자인을 통계적으로 하나씩 하나씩 해석해 보겠습니다. |
|
|
해석을 해보면,
Experiment Phase (실험 단계): Method Development
이 실험은 방법 개발 단계에 있습니다.
Experiment Type (실험 유형): Screening
이 실험은 여러 변수들 중에서 중요한 변수들을 선별하기 위한 것입니다.
Design Type (설계 유형): A- and G-optimal Process (Model Robust) - Screening
A-최적화와 G-최적화 설계 유형을 사용하여 선별 과정을 수행합니다. 이러한 설계는 실험의 효율성을 높이고 강건한 모델을 구축하는 데 도움이 됩니다.
Design Model (설계 모델): Quadratic (이차)
이 설계 모델은 이차 모형을 사용하여 변수 간의 관계를 설명합니다. 이차 모형은 변수들 간의 상호작용과 곡선형 관계를 고려할 수 있습니다. |
|
|
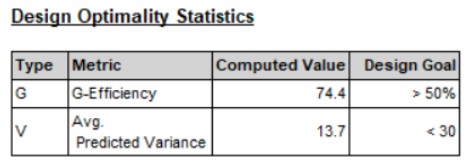
G-효율성(G-Efficiency)은 실험 계획법(Design of Experiments, DOE)에서 실험 설계의 효율성을 평가하는 중요한 지표 중 하나입니다. G-효율성은 설계된 실험이 얼마나 효과적으로 다양한 변수의 효과를 추정할 수 있는지를 나타냅니다. 더 높은 G-효율성 값은 실험 설계가 보다 효율적임을 의미합니다. G-효율성은 0에서 100 사이의 값을 가지며, 100에 가까울수록 이상적인 설계임을 의미합니다.
계산된 값은 74.4로, 이는 목표치인 50% 이상을 충족합니다. 이는 설계가 효율적임을 의미합니다.
평균 예측 분산(Avg. Predicted Variance)은 실험 계획법에서 중요한 통계적 지표로, 실험 데이터로부터 모델을 구축할 때 예측의 정확도를 평가하는 데 사용됩니다. 이 값은 모델이 예측하는 값의 분산(variability)을 나타내며, 일반적으로 낮을수록 좋습니다. 낮은 평균 예측 분산은 모델이 실험 데이터로부터 변수의 효과를 더 정확하게 예측할 수 있음을 의미합니다.
평균 예측 분산은 실험 결과의 예측 정확도를 나타냅니다. 계산된 값은 13.7로, 이는 목표치인 30보다 작습니다. 이는 예측 모델이 안정적이고 정확하다는 것을 의미합니다. |
|
|
G-Efficiency 값이 50% 이상이고 평균 예측 분산 값이 30이하로 잡는 이유는 무엇일까요?
G-효율성의 목표: 50% 이상
- 효율성 보장: G-효율성 50% 이상은 설계가 최소한의 효율성을 보장한다는 의미입니다. 이는 실험 설계가 변수들의 주효과 및 상호작용을 신뢰성 있게 추정할 수 있도록 하는 기본적인 기준입니다.
- 설계 품질: 50% 이상은 설계가 어느 정도 균형 잡혀 있으며, 실험 포인트가 변수 공간에 고르게 분포되어 있음을 나타냅니다. 이는 실험 결과의 변동성을 줄이고, 신뢰성 높은 결과를 도출하는 데 중요합니다.
- 실용적인 이유: 너무 높은 목표를 설정하면 실험 비용이 증가하고, 실행 가능성이 낮아질 수 있습니다. 50%는 실용성과 효율성의 균형을 맞추는 합리적인 목표입니다.
평균 예측 분산의 목표: 30 이하
- 예측 정확도 보장: 평균 예측 분산 30 이하를 목표로 하면, 모델이 예측하는 값들의 변동성이 적어, 예측 정확도가 높아집니다. 이는 실험 결과의 신뢰성을 높이고, 변수의 효과를 정확히 추정할 수 있도록 합니다.
- 모델 안정성: 낮은 예측 분산은 모델이 다양한 조건 하에서도 일관된 성능을 발휘할 수 있음을 나타냅니다. 이는 실험 데이터를 바탕으로 한 모델이 다양한 상황에서도 안정적으로 작동하도록 합니다.
- 결과의 해석 용이성: 예측 분산이 낮으면, 실험 결과 해석이 용이해지고, 결과에 대한 신뢰도가 높아집니다. 이는 실험 후속 단계에서 의사 결정을 내리는 데 중요한 역할을 합니다.
종합적인 이유
- 균형 있는 설계: 목표 설정은 실험 설계가 효율성과 정확성을 모두 갖추도록 유도합니다. 이는 실험 결과가 신뢰성 있고, 실험 자체가 경제적으로 실행 가능하도록 합니다.
- 표준화된 기준: 특정 기준을 설정하면, 다양한 실험에서 일관된 품질을 유지할 수 있습니다. 이는 실험 결과를 비교하거나 통합할 때 유리합니다.
- 최적화 과정의 가이드라인: 설정된 목표는 실험 설계를 최적화할 때 가이드라인 역할을 합니다. 이를 통해 실험자가 효율적이고 신뢰성 높은 설계를 달성할 수 있도록 돕습니다.
결론적으로, G-효율성과 평균 예측 분산에 대한 목표를 설정하는 것은 실험의 품질을 보장하고, 실험 결과의 신뢰성을 높이는 데 중요한 역할을 합니다. 이는 실험 설계의 효율성, 예측 정확도, 그리고 실용성을 균형 있게 유지하기 위한 전략입니다. |
|
|
평균 예측 분산범위가 30 이하라는 의마는 무엇일까요?
평균 예측 분산의 범위
- 이론적 범위:
- 평균 예측 분산은 항상 0 이상입니다. 이는 분산이 음수일 수 없기 때문입니다.
- 상한선은 데이터와 모델의 복잡성, 실험 설계의 특성에 따라 달라지며, 이론적으로 무한대까지 갈 수 있지만 실용적인 의미에서는 적절한 범위 내에서 유지됩니다.
- 실용적 범위:
- 낮은 값 (0에 가까움): 예측 분산이 0에 가까운 경우, 모델이 매우 정확하게 예측하고 있음을 의미합니다. 그러나 이는 거의 완벽한 모델을 가정하는 것이며, 실제로는 다양한 변동성을 고려해야 하므로 거의 불가능합니다.
- 중간 값 (10-30): 일반적으로 목표로 설정되는 범위입니다. 예를 들어, 특정 실험에서는 평균 예측 분산이 30 이하로 설정되는 경우가 많습니다. 이는 모델의 예측이 신뢰할 수 있는 수준임을 나타냅니다.
- 높은 값 (30 이상): 예측 분산이 30을 초과하는 경우, 모델의 예측 변동성이 크고, 예측 정확도가 낮을 수 있습니다. 이는 실험 설계가 비효율적이거나, 데이터가 충분하지 않음을 시사할 수 있습니다.
|
|
|
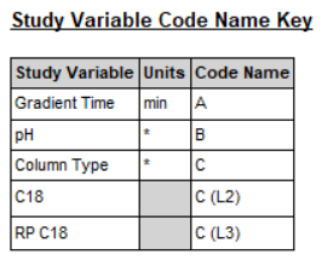
- Gradient Time은 'A'로 코딩되며, 분 단위로 측정됩니다.
- pH는 'B'로 코딩되며, 특정 단위가 없습니다.
- Column Type은 'C'로 코딩되며, 특정 단위가 없습니다.
- C18 컬럼 유형은 'C (L2)'로 코딩됩니다.
- RP C18 컬럼 유형은 'C (L3)'로 코딩됩니다.
|
|
|
각 열의 의미
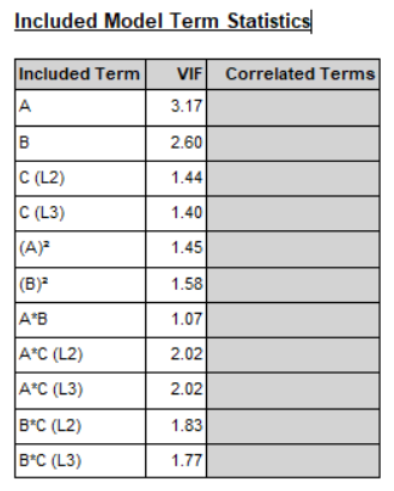
- Included Term: 모델에 포함된 항(term)을 나타냅니다.
- VIF (Variance Inflation Factor): 분산 팽창 계수로, 각 독립 변수 간의 다중 공선성(Multicollinearity)을 측정합니다. VIF 값이 높을수록 다중 공선성이 높아집니다.
VIF 값 해석
VIF(분산 팽창 계수)는 회귀 분석에서 다중 공선성 ( Multicollinearity )을 평가하는 지표입니다. 일반적으로 VIF 값이 10을 초과하면 다중 공선성이 높다고 간주하지만, 보수적인 기준으로는 5를 초과할 때 다중 공선성 문제를 의심합니다.
- A (3.17): VIF 값이 3.17로, 다중 공선성의 가능성이 약간 있지만 심각하지 않은 수준입니다.
- B (2.60): VIF 값이 2.60로, 다중 공선성이 약간 있을 수 있지만, 일반적으로 허용되는 수준입니다.
- C (L2) (1.44): VIF 값이 1.44로, 다중 공선성이 거의 없습니다.
- C (L3) (1.40): VIF 값이 1.40로, 다중 공선성이 거의 없습니다.
- (A)² (1.45): VIF 값이 1.45로, 다중 공선성이 거의 없습니다.
- (B)² (1.58): VIF 값이 1.58로, 다중 공선성이 거의 없습니다.
- A*B (1.07): VIF 값이 1.07로, 다중 공선성이 거의 없습니다.
- A*C (L2) (2.02): VIF 값이 2.02로, 다중 공선성이 약간 있을 수 있지만, 허용 가능한 수준입니다.
- A*C (L3) (2.02): VIF 값이 2.02로, 다중 공선성이 약간 있을 수 있지만, 허용 가능한 수준입니다.
- B*C (L2) (1.83): VIF 값이 1.83로, 다중 공선성이 약간 있을 수 있지만, 허용 가능한 수준입니다.
- B*C (L3) (1.77): VIF 값이 1.77로, 다중 공선성이 약간 있을 수 있지만, 허용 가능한 수준입니다.
종합 설명
이 표는 회귀 모델에 포함된 각 항의 VIF 값을 나타내며, 이를 통해 다중 공선성의 정도를 평가할 수 있습니다. 주어진 값들을 보면, 대부분의 항이 다중 공선성 문제를 일으키지 않는 수준에 있습니다. VIF 값이 5를 초과하지 않으므로, 모델의 예측 성능에 큰 문제가 없을 것으로 보입니다. 다만, A의 VIF 값이 상대적으로 높으므로 이 항의 다중 공선성을 주의 깊게 모니터링할 필요가 있습니다.
다중공선성(Multicollinearity)은 회귀 분석에서 독립 변수들 간에 높은 상관관계가 있는 경우를 말합니다. 다중공선성은 회귀 모델의 추정 및 해석에 여러 가지 문제를 일으킬 수 있습니다.
아래에 다중공선성에 대한 더 자세한 설명을 말씀드립니다. |
|
|
다중공선성(Multicollinearity)의 개념
다중공선성은 다음과 같은 경우에 발생합니다:
- 회귀 분석에서 하나의 독립 변수가 다른 독립 변수들의 선형 조합으로 표현될 수 있을 때.
- 여러 독립 변수들이 서로 높은 상관관계를 가질 때.
이런 경우 회귀 계수의 추정치가 매우 불안정해지고, 작은 데이터 변화에도 큰 변동을 일으킬 수 있습니다.
다중공선성의 영향
- 회귀 계수의 불안정성: 독립 변수들 간의 상관관계가 높으면 회귀 계수의 표준 오차가 커져서, 추정치가 불안정해집니다.
- 해석의 어려움: 다중공선성으로 인해 각 독립 변수가 종속 변수에 미치는 영향을 분리하여 해석하기 어려워집니다.
- 통계적 유의성의 왜곡: 다중공선성이 있는 경우 t-검정 결과가 왜곡될 수 있으며, 이는 특정 변수의 통계적 유의성을 잘못 판단하게 할 수 있습니다.
- 예측 성능 저하: 다중공선성이 높은 모델은 예측 성능이 저하될 수 있으며, 새로운 데이터에 대한 일반화 능력이 떨어질 수 있습니다.
다중공선성의 진단
다중공선성을 진단하기 위해 사용하는 주요 지표는 VIF(Variance Inflation Factor, 분산 팽창 계수)입니다.
- VIF: 특정 독립 변수가 다른 독립 변수들과 얼마나 상관관계가 있는지를 나타냅니다. VIF 값이 1에 가까울수록 다중공선성이 없음을 의미하며, 값이 클수록 다중공선성이 높음을 의미합니다.
- 일반적으로 VIF 값이 10을 초과하면 다중공선성 문제가 있다고 간주합니다.
- 보수적인 기준으로는 VIF 값이 5를 초과할 때 다중공선성을 의심할 수 있습니다.
다중공선성의 해결 방법
- 변수 제거: 높은 상관관계를 갖는 변수를 모델에서 제거할 수 있습니다.
- 변수 결합: 상관관계가 높은 변수들을 결합하여 하나의 변수로 만들 수 있습니다.
- 주성분 분석(PCA): 독립 변수들을 몇 개의 주성분으로 변환하여 다중공선성을 줄일 수 있습니다.
정규화 기법: 릿지 회귀(Ridge Regression)와 같은 정규화 기법을 사용하여 회귀 계수의 추정치를 안정화할 수 있습니다. |
|
|
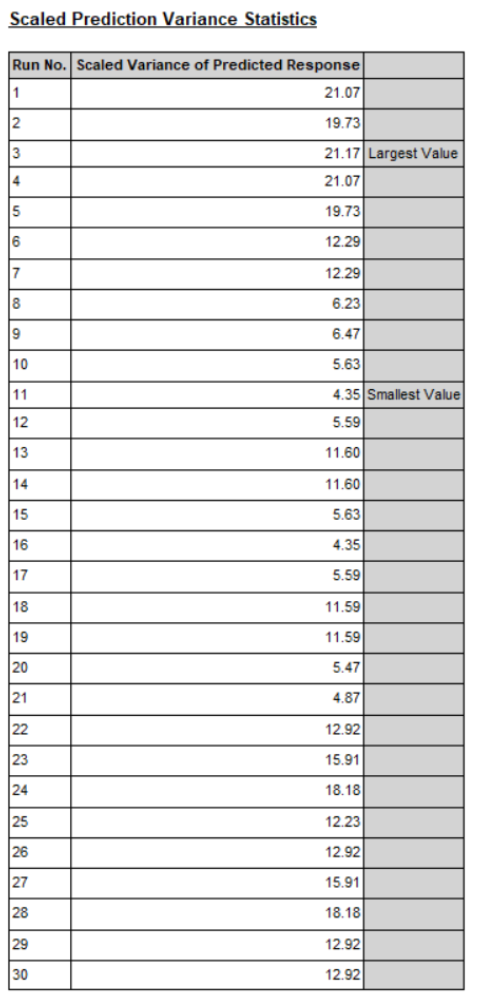
예측 분산은 모델이 주어진 조건에서 예측하는 값들의 변동성을 나타내며, 스케일링된 예측 분산은 이 값을 일정한 척도로 조정하여 비교하기 쉽게 만든 것입니다. 예측 분산이 낮을수록 모델의 예측이 더 정확함을 의미합니다.
주요 지점
- Largest Value (가장 큰 값):
- Run No. 3: 21.17
- 이 값은 예측 분산이 가장 큰 경우를 나타내며, 모델의 예측 변동성이 가장 큽니다.
- Smallest Value (가장 작은 값):
- Run No. 11: 4.35
- 이 값은 예측 분산이 가장 작은 경우를 나타내며, 모델의 예측 변동성이 가장 작습니다.
해석
- 예측 분산의 크기:
- 높은 예측 분산 (예: Run No. 1, 2, 3, 4, 5)은 해당 조건에서 모델의 예측이 불안정하고 변동성이 큼을 의미합니다. 이는 특정 조건에서 모델의 신뢰성이 낮을 수 있음을 시사합니다.
- 낮은 예측 분산 (예: Run No. 11, 16)은 해당 조건에서 모델의 예측이 안정적이고 변동성이 적음을 의미합니다. 이는 특정 조건에서 모델의 신뢰성이 높을 수 있음을 시사합니다.
- 평균 예측 분산:
- 평균 예측 분산 값은 전체 예측 분산의 평균을 계산하여 모델의 전반적인 예측 정확도를 평가하는 데 사용됩니다.
- 특정 런(run)에서 예측 분산이 매우 높거나 낮은 경우를 주의 깊게 살펴보고, 이러한 런들이 전체 모델에 미치는 영향을 평가할 필요가 있습니다.
종합적인 결론
이 표는 각 실험 실행에 대한 예측 분산을 보여주며, 이를 통해 모델의 예측 정확도를 평가할 수 있습니다. 높은 예측 분산은 모델의 예측이 해당 조건에서 불안정하다는 것을 의미하며, 낮은 예측 분산은 안정적이라는 것을 의미합니다. 이를 바탕으로 모델의 성능을 개선하거나 특정 조건에서의 예측 정확도를 높이기 위한 추가 조치를 고려할 수 있습니다. |
|
|
긴 내용이지만 많은 분들이 궁금해 하시는 내용이기에 공유해보았습니다.
다음에는 실험된 내용을 가지고 결과를 어떻게 해석할 것인가를 알아보겠습니다.
감사합니다.
|
|
|
(주)랩솔루션즈
주소: 경기도 광명시 덕안로 104번길 17, 광명역엠클러스터 1003호, 전화번호: 02-896-4648 수신거부 Unsubscribe |
|
|
|
|